打破CAP理论!TiKV如何用分布式存储颠覆数据库界?
当双十一订单崩溃时,我们真的无能为力吗?
去年双十一,某个电商平台凌晨系统崩了,高峰期数据库慢得要死,大家付款各种失败,当时开发者们都快疯了。其实很多的公司都头疼数据库扩展的问题。那本期就来聊聊这个问题, 主角 GitHub 上一个 16k 星的开源项目给出的意想不到的答案。

今天我们要聊的主角 TiKV,这玩意儿让数据库专家们又佩服又好奇。它像个瑞士军刀,既保证数据不出错(ACID特性),又能像 NoSQL 一样随便扩展。咱们来扒一扒这个中国团队搞的分布式存储引擎。
TiKV 咋就打破了数据库界的“不可能三角”?
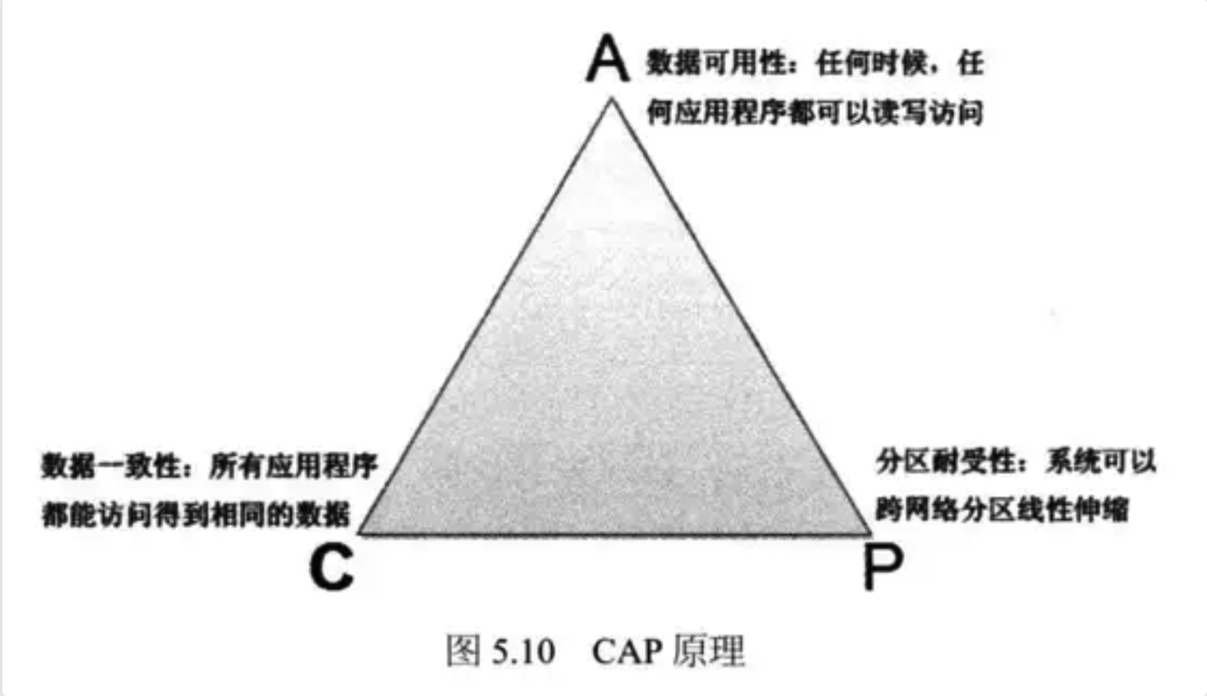
CAP理论的世纪难题
你是否经历过这样的尴尬时刻: - 电商大促时系统卡顿 - 跨行转账出现数据不一致 - 传统数据库在分布式场景下总让我们陷入两难境地
这就是困扰业界数十年的CAP理论困境。要么牺牲一致性,要么降低可用性,要么放弃扩展性。而TiKV的出现,就像在量子物理领域发现了新的粒子,给这个看似无解的问题带来了新解法。
技术革命的三大突破
| 传统方案缺陷 | TiKV创新方案 | 实测效果 |
|---|---|---|
| 分布式事务难以保障 | Region-based Sharding+Raft协议 | 500,000 TPS吞吐量,支持 100+ TB 数据的水平可扩展性 |
| 水平扩展困难 | 动态负载均衡算法 | 资源利用率提升40% |
| 多数据中心部署复杂 | Geo-Replication技术 | 延迟<50ms |
有个叫小王的开发者说:“用了 TiKV 改造库存系统,双十一 72 小时没出问题,运维成本直接减了一半。”
这个架构设计有多精妙?看懂就能少踩坑
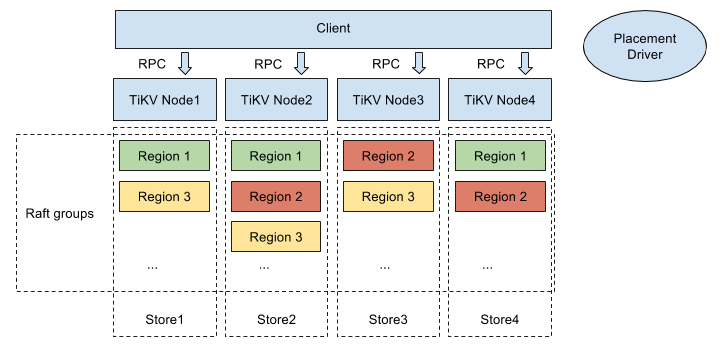
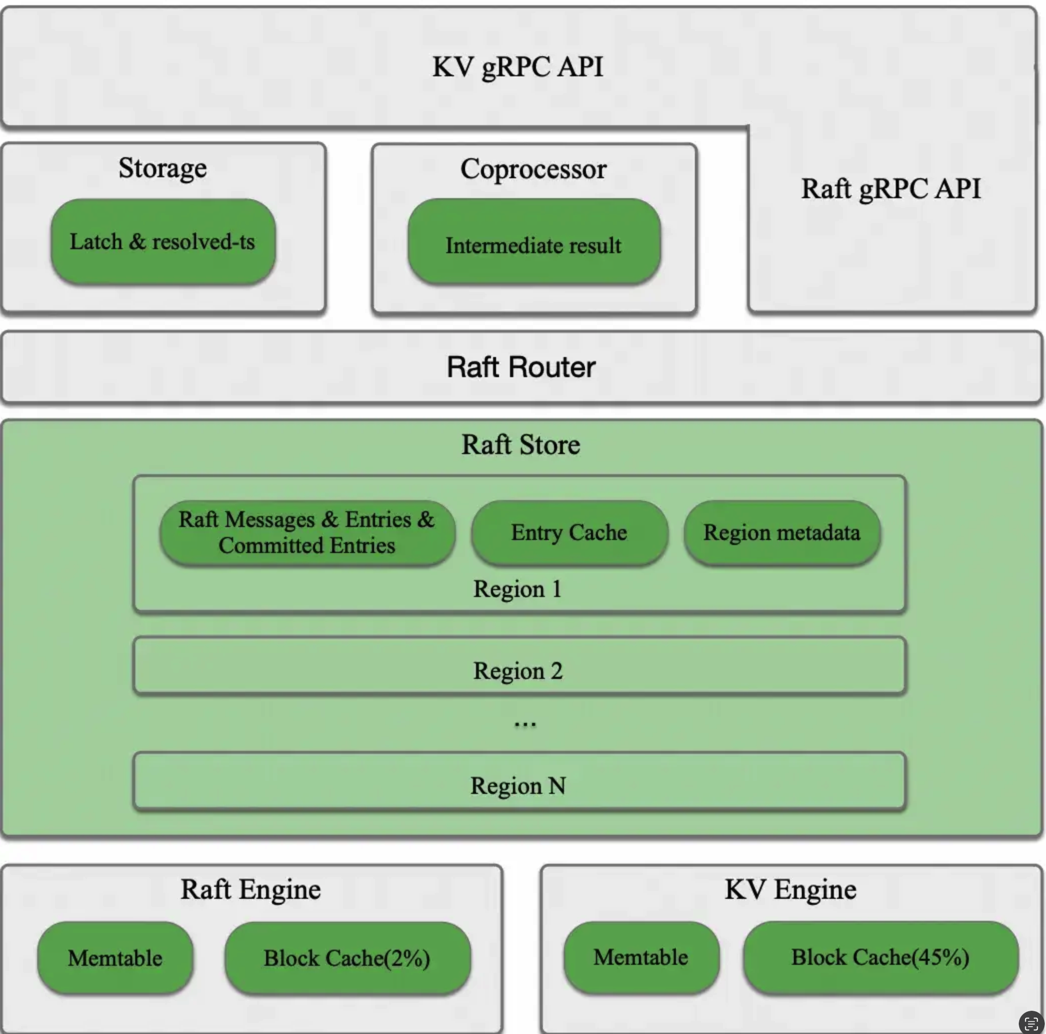
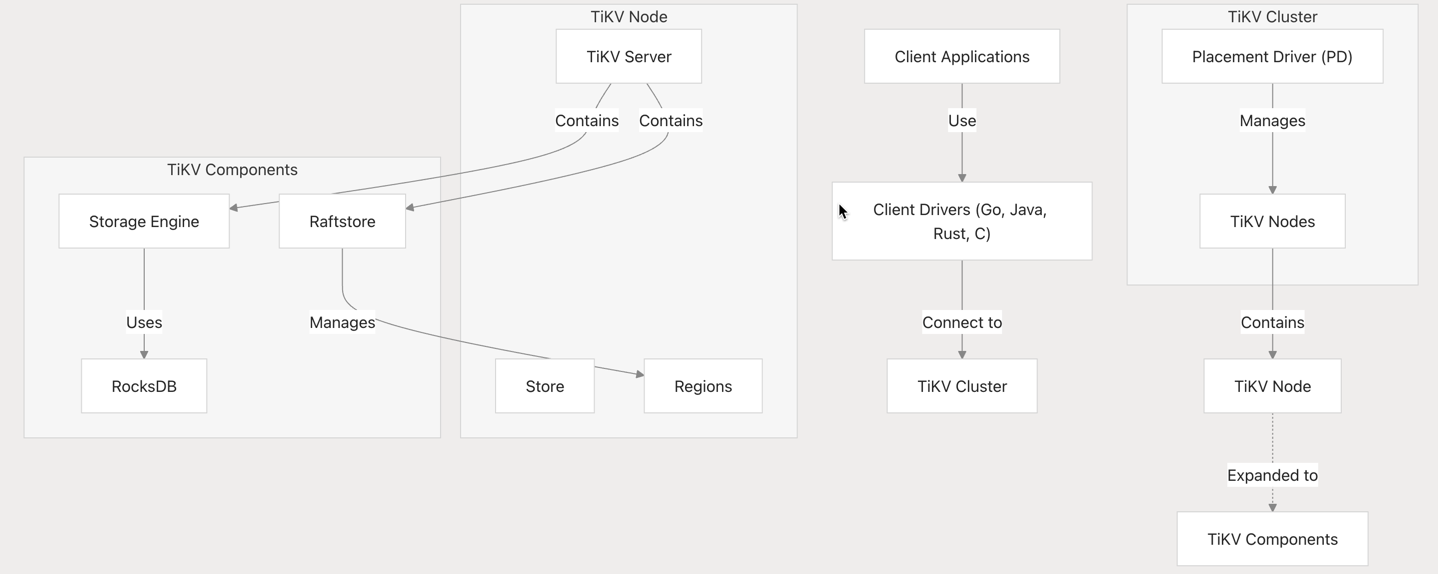
这套架构的核心智慧在于: 1. 智能调度:PD 调度器随时监控集群,自动分配任务。 2. 弹性伸缩:加个新节点,15 分钟内搞定数据迁移。 3. 云原生:Kubernetes一键搞定部署,资源利用率提高 40%。
小知识:TiKV 的名字来自化学元素钛(Ti),表示稳定和坚固。它的代码包含了完整的 Raft 算法实现,成了不少分布式课程的经典教材。
真实战场上的表现有多惊艳?
金融行业标杆案例
某股份制银行采用TiKV构建实时风控系统,将反欺诈决策时间从200ms压缩至20ms。CTO坦言:"这是我们在合规前提下首次实现全链路实时监控。"
游戏行业创新玩法
某头部游戏公司用 Coprocessor 开发了动态定价系统,新版本上线时,成功应对了每天 3000 万次的皮肤购买请求。运维负责人说:“这就像给数据库装了个自动驾驶。”
| 评估维度 | TiKV | MySQL Cluster | Cassandra |
|---|---|---|---|
| 事务支持 | ✅ ACID | ❌ | ❌ |
| 扩展性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 多数据中心部署 | ✅ Geo-Replication | ❌ | ✅(部分支持) |
15分钟体验分布式数据库的秘密
想自己试试的开发者,可以用 TiUP 快速部署::
# 安装管理工具
curl --proto "=https" --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
# 创建本地集群
tiup playground v7.5.0
Python客户端验证代码:
from tikv_client import RawClient
client = RawClient.connect("127.0.0.1:2379")
client.put(b"user:1001", b"{"name":"Alice","score":99}")
print(client.get(b"user:1001"))
# 输出: b"{"name":"Alice","score":99}"
未来发展的三个重点
- HTAP 场景:和 TiDB 搭配,同时支持在线交易和数据分析。
- 边缘计算:通过 Region 分割,就近访问,加快响应速度 60%。
- Serverless:最新版本有 AutoScaler 组件,能根据负载自动调整机器数量。
核心开发者说:“我们不做华而不实的东西,只想解决开发者们头疼的问题“
给开发者的建议
✅ 入门路径: 1. 从官方文档的 Contribution Guide 开始。 2. 参与 GitHub Discussions 的技术讨论。 3. 在社区 Slack 频道寻求帮助。
💡 进阶技巧: - 用 Coprocessor 框架在存储层做聚合计算。 - 通过 Placement Driver 的智能调度算法优化资源分配。 - 用 Rust 语言避免空指针和缓冲区溢出。
结语:未来的技术希望
TiKV 在云原生时代展现出了活力。它证明了中国开源不仅能参与国际竞争,还能给全球开发者提供新方案。对开发者来说,选择多了,不用只会复制粘贴了。
如果你正在寻找一款既能应对高并发场景,又能保障数据一致性的分布式数据库,不妨亲自体验TiKV的魅力。毕竟在这个数据驱动的时代,选择正确的工具,往往意味着事半功倍的开始。

延伸思考:当你的项目面临百万级QPS压力时,除了传统的Sharding方案,是否考虑过用TiKV的Region-based Sharding架构来重构系统?欢迎在评论区分享你的实践经验!
关注 GitHubShare(githubshare.com),发现更多精彩内容!
感谢大家的支持!你们的支持是我继续更新的动力❤️
- 本文标签: Rust 分布式存储 DistributedDB
- 本文链接: https://www.githubshare.com/article/2894
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
热门推荐










相关文章
关于
