高效处理文本的利器:FastText 🚀
License
MIT
Stars
26.3k
Forks
4.8k
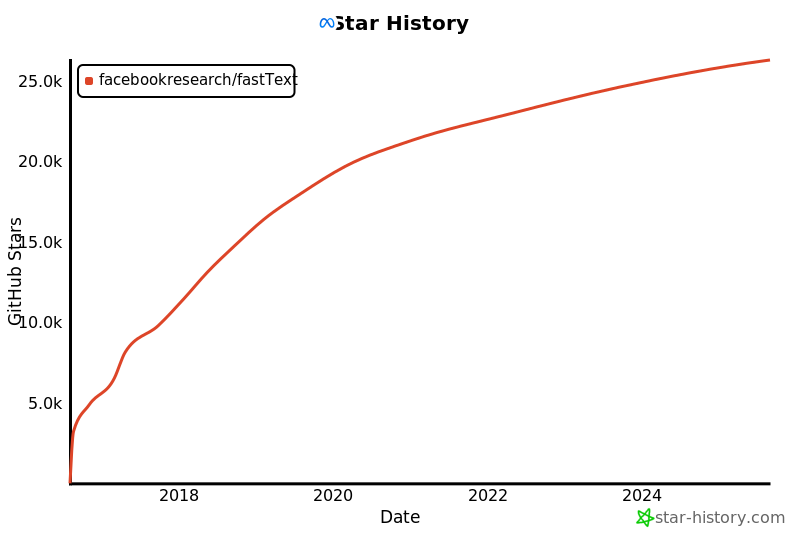
摘要
FastText 是 Facebook AI Research 团队开发的一款开源软件,专注于高效词向量生成与文本分类。其基于子词信息建模,解决了传统 NLP 工具在效率和多语言适配方面的痛点。GitHub 上获得超过 26k 星标,被广泛应用于多个领域。
内容
你是否还在为文本处理而烦恼?那就来认识一下 FastText 吧!这个由 Facebook 研究院开发的开源项目,专为快速学习词向量和文本分类而生。它不仅速度快,还能轻松应对多语言场景哦~
FastText 的核心功能包括两个方面:**词表示学习**和**文本分类**。通过子词建模(subword information),它可以更灵活地处理拼写变体或低资源语言问题。例如,你可以用简单的命令训练出自己的词向量模型,如 `./fasttext skipgram -input data.txt -output model`。
另外,FastText 还能进行监督式文本分类。无论是情感分析还是法律文档处理,它的表现都相当不错。而且,它的预训练模型已经支持 157 种语言,这在 NLP 领域是非常实用的功能了。
说到热度,FastText 在 GitHub 上获得了超过 26,000 颗星标,以及 4,800 次 Fork,可见其受欢迎程度不低。社区中也有不少人讨论它的使用技巧和扩展应用,比如一些论文还验证了其在特定任务中的高准确率。
如果你是个技术小白,FastText 提供了“开箱即用”的体验,无需深挖算法即可上手。对于有经验的开发者来说,它高效的训练速度和易用性是加分项。此外,MIT 许可证也让商业和学术使用更加自由。
总之,FastText 是一个值得一看的工具,尤其适合那些需要快速部署、节省资源或处理多语言任务的用户。更多详情可查看官方文档,或者动手试试看吧!😊
关键词
分类
热门推荐










相关文章
关于
