非结构化数据处理难题终结者:Milvus让AI应用秒级响应
在当今这个人工智能和机器学习快速发展的时代,我们每天都在接触大量非结构化的数据——比如文本、图像、音频。这些数据不像传统的表格那样整齐划一,它们更像是“乱麻”,难以直接处理。
你是否遇到过这样的情况?开发一个智能客服系统时,每次查询都要花费几秒钟甚至更长时间,用户体验大打折扣。这正是许多 AI 项目中常见的痛点。而今天我们要介绍的开源项目 Milvus,或许能帮你解决这些问题。
为什么传统数据库难以应对 AI 的需求?

想象一下,你在做一个电商平台的推荐系统,需要根据用户的行为和兴趣找到相似的商品进行推荐。但随着商品数量的增长,传统的数据库已经无法满足需求。每次查询都要等待几秒甚至几分钟,用户体验大受影响。
这种情况在 AI 领域并不罕见。尤其是当我们面对数十亿条数据时,传统方法显得力不从心。一方面,我们需要高效的相似性搜索;另一方面,又要兼顾实时更新和扩展性。这两者之间的矛盾,正是许多团队面临的瓶颈。
官方测试数据显示,在某些场景下,Milvus 的性能比主流方案提升了 300% 以上。这意味着,如果你曾经因为数据检索效率低而头疼不已,现在有了更好的选择。
Milvus 是什么?一句话解释
简单来说,Milvus 是一个专门用于处理向量数据的数据库。你可以把它看作是一个“智能大脑”,帮助你的 AI 应用更快地找到答案。无论是文本、图片还是音频,只要你能将其转换成向量,Milvus 就能帮你高效存储和检索。
它的目标很明确:让大规模向量搜索变得像操作普通数据库一样简单。为此,它采用了 Go 和 C++ 编写,利用了 GPU 加速和多种先进的索引算法,确保在高并发、大数据量的情况下依然保持稳定和高效。
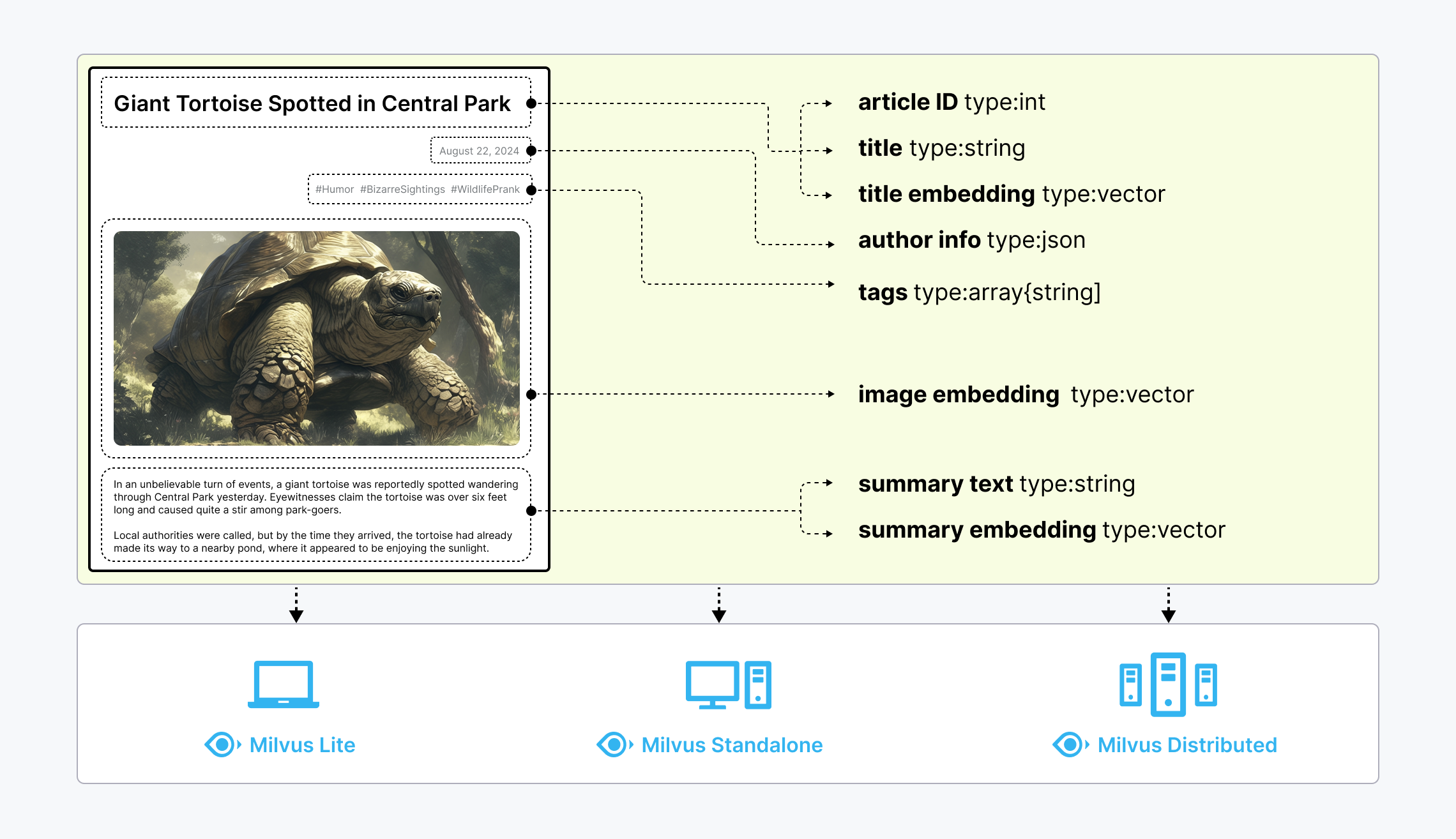
核心功能一览
- ⚡ 高性能向量搜索:支持 HNSW、IVF-PQ、DiskANN 等多种索引类型,适应不同场景
- 🐳 云原生架构:Kubernetes 原生设计,便于水平扩展和部署
- 🔁 实时数据流处理:支持实时数据注入,保证信息的最新性
- 🌐 多模态数据支持:可以同时处理文本、图像、音频等多种数据形式
- 🔄 混合搜索能力:结合向量相似性和传统标量过滤,提高查询精度
- 🛡️ 安全与成本控制:支持 TLS 加密和热/冷存储策略,兼顾安全性与经济性
技术亮点对比
| 特性 | Milvus | 传统数据库 |
|---|---|---|
| 向量搜索 | ✅ 支持多种高效索引 | ❌ 通常不支持 |
| 分布式架构 | ✅ Kubernetes 原生 | ❌ 多数为单机模式 |
| 实时更新 | ✅ 支持流式数据 | ❌ 更新较慢 |
| 多模态支持 | ✅ 可处理多种数据 | ❌ 一般只处理结构化数据 |
| 易用性 | ✅ 提供 Python SDK | ❌ 接口复杂 |
这些对比不仅展示了 Milvus 的独特之处,也说明了它为什么能在众多开源项目中脱颖而出。
使用体验:从零到一只需几分钟
Milvus 的安装和使用非常简便,尤其适合刚入门的开发者。以下是一个简单的步骤:
-
安装 pymilvus SDK
bash pip install -U pymilvus这一步即可开始使用 Milvus 的 Python API。 -
创建本地数据库实例
python from pymilvus import MilvusClient client = MilvusClient("milvus_demo.db") -
创建集合并定义维度
python client.create_collection( collection_name="demo_collection", dimension=768 # 向量的维度 ) -
插入数据
python data = [ {"vector": [0.1, 0.2, ...], "text": "示例文本1"}, {"vector": [0.3, 0.4, ...], "text": "示例文本2"} ] res = client.insert(collection_name="demo_collection", data=data) -
执行搜索
python query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?", "What is AI?"]) res = client.search( collection_name="demo_collection", data=query_vectors, limit=2, output_fields=["vector", "text", "subject"] )
整个过程只需要几分钟,就能让你的 AI 应用具备强大的向量搜索能力。
当然,初次安装可能会遇到一些小问题,比如依赖冲突或者版本不兼容。不过,社区提供了详细的文档和频繁的更新,帮助你快速解决这些问题。
如果你不想自己搭建环境,也可以通过 Zilliz Cloud 或 GitPod 快速在线体验 Milvus。这样,即使你没有服务器资源,也能轻松尝试这项技术。

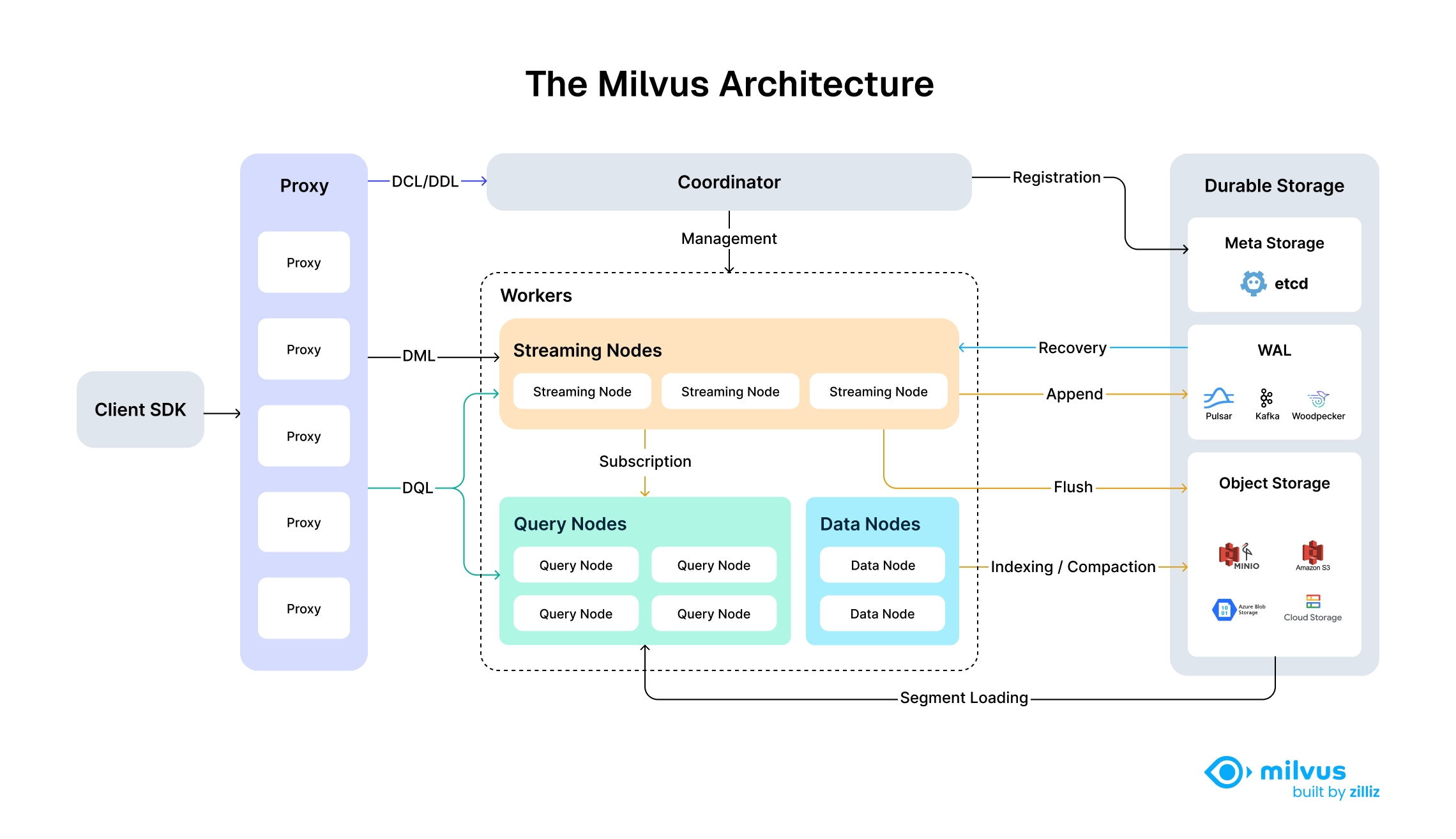
架构解析:深入理解 Milvus 的设计哲学
Milvus 的设计哲学可以概括为三点:灵活性、性能和可靠性。为了实现这一点,它采用了多个关键技术。
存储与计算分离
Milvus 的架构将存储和计算分开,允许独立扩展。例如,如果你的应用主要是读取数据,你可以增加更多的查询节点;如果是写入为主,则可以增加数据节点。这种设计避免了资源浪费,同时也提高了系统的整体稳定性。
模块化设计:各司其职,协同工作
Milvus 的核心模块包括: - IndexCoord:负责协调索引的构建和搜索。 - QueryNode:执行具体的查询任务。 - DataNode:负责数据的持久化和管理。
每个模块都以微服务的形式运行,彼此之间通过 gRPC 进行通信。这种设计不仅提高了系统的可维护性,还增强了容错能力。
为何选择 Go 和 C++?
Go 以其并发模型和编译速度快著称,非常适合构建高性能的网络服务。而 C++ 则在底层性能优化方面表现出色。Milvus 结合了两者的优势:Go 负责上层逻辑和服务调度,C++ 则用于高性能的向量搜索引擎(Knowhere)。这种组合既保证了系统的响应速度,又保留了足够的灵活性。
性能优化策略
- 内存管理:Milvus 对内存进行了精细的管理,减少 GC(垃圾回收)带来的性能损耗。
- 索引算法选择:根据不同的应用场景,Milvus 提供了多种索引选项,如 HNSW 适用于高精度场景,IVF-PQ 更适合大规模数据。
- 负载均衡:在集群环境下,Milvus 会自动分配查询任务,避免某个节点过载。
社区与生态
Milvus 的成功离不开其活跃的开源社区。截至 2025 年 8 月,该项目已经在 GitHub 上获得了超过 36,800 颗星标,并吸引了 293 名贡献者。丰富的文档、活跃的讨论区和及时的 issue 响应,使得 Milvus 成为一个易于上手且持续进化的项目。
此外,Zilliz 作为主要贡献者,推出了托管服务 Zilliz Cloud,为用户提供 Serverless、Dedicated 和 BYOC 三种部署模式。这种商业与开源的结合,不仅降低了使用门槛,也让企业能够专注于业务逻辑而非基础设施。
更重要的是,Milvus 已经被纳入多篇学术论文的研究对象,显示出其在技术和理论层面的双重价值。虽然它尚未成为行业巨头的标配,但在 AI 开发圈内已经广受好评。
Milvus 的实际应用案例
某知名电商平台曾面临一个挑战:用户上传了大量商品图片,传统的图像匹配方法无法满足实时推荐的需求。他们尝试了多个解决方案后,最终选择了 Milvus。通过将每张图片转换为嵌入向量并存储在 Milvus 中,他们成功将推荐响应时间从 5 秒缩短到了 500 毫秒以内。这一改进不仅提升了用户体验,还显著增加了转化率。
另一个例子是自然语言处理中的语义搜索。假设你正在构建一个智能问答系统,需要从海量文档中找到最相关的信息。Milvus 通过语义向量,可以帮助你快速定位答案,提升搜索的准确性和效率。
未来展望:Milvus 的发展方向
随着 AI 技术的不断发展,Milvus 也在不断演进。目前,它已经展现出在多模态数据处理方面的潜力。未来的版本可能会进一步提升跨平台兼容性,让更多开发者能够无缝集成到自己的项目中。
与此同时,Zilliz 正在推动 Milvus 在更多垂直领域的落地,比如医疗影像分析、金融风控等。这些场景对数据的实时性和准确性要求极高,而 Milvus 的分布式架构和硬件加速特性正好能满足这些需求。
如何参与 Milvus 的发展?
如果你对 Milvus 感兴趣,不妨加入其 Discord 社区。那里有无数热情的开发者等着与你交流经验。也许下一个爆款 AI 应用,就出自你的手中!
此外,你还可以访问 GitHub 项目主页 或 Zilliz Cloud,了解更多关于 Milvus 的技术细节和使用方式。
结语:重新思考 AI 数据管理的可能性
Milvus 的出现,标志着向量数据库领域的一次重要进步。它不仅解决了 AI 应用中的核心问题,还为开发者提供了友好的接口和强大的性能。随着 AI 技术的不断发展,Milvus 有望在更多领域发挥重要作用。
如果你正在寻找一种高效、可靠的方式来处理非结构化数据,不妨试试 Milvus。它或许不能立刻带来革命性的变化,但它一定能为你节省时间、提升效率。而且,作为一个开源项目,你还可以参与到它的开发中,共同推动这一领域的进步。
欢迎留言分享你的想法,或者谈谈你在 AI 项目中遇到过的数据管理难题。也许我们可以一起找到更好的解决方案!
关注 GitHubShare(githubshare.com),发现更多精彩内容!
感谢大家的支持!你们的支持是我继续更新的动力❤️
热门推荐










相关文章
关于
