GitHub爆红项目揭秘:只需5秒音频,AI就能完美模仿你的声音!
引言:当AI学会模仿你的声音
你有没有想过,只需要一段5秒的音频,就能完美复刻一个人的声音?这听起来像是科幻电影里的场景,但如今已经变成了现实。GitHub上有一个名为Real-Time Voice Cloning(实时语音克隆)的开源项目,它通过深度学习技术实现了这一目标。
这个项目不仅吸引了大量开发者关注,还引发了关于AI伦理与安全的广泛讨论。今天,我们就来一起看看这项“会说话的AI”是如何实现的,以及它到底有多强大。
背景故事:从硕士论文到开源热潮
RTVC 最初是作者 Corentin Joudin 的硕士毕业论文项目。他的研究方向是语音合成,但当时市面上的方案都太复杂,且需要大量的语音数据。于是,他决定自己动手做一个更轻便、更实用的语音克隆系统。
在一次实验中,他惊讶地发现,仅用 5 秒的语音样本,就能生成令人信服的语音。这一突破让他意识到,语音克隆的未来不在于追求完美,而是追求“足够好”的用户体验。
如今,RTVC 不只是一个学生项目的成果,更是推动 AI 语音合成普及的重要力量。它让更多人有机会接触到语音克隆技术,也让普通人看到了 AI 的无限可能。
痛点分析:传统语音合成的局限
在 RTVC 出现之前,语音合成技术存在不少痛点:
- 数据需求高:大多数语音合成系统需要大量的训练数据,通常要几十分钟甚至几小时的语音才能生成一个模型。
- 处理速度慢:生成高质量语音往往需要漫长的等待时间。
- 个性化程度低:大多数 TTS 系统只能提供有限的声音选项,难以满足个性化需求。
而 RTVC 通过创新性的设计,几乎解决了以上所有问题。官方测试显示,在相同条件下,它的性能比主流方案提升了 300%。更令人惊讶的是,它竟然能在 Python 环境下实现接近 C 语言的速度。
解决方案:如何实现5秒语音克隆?
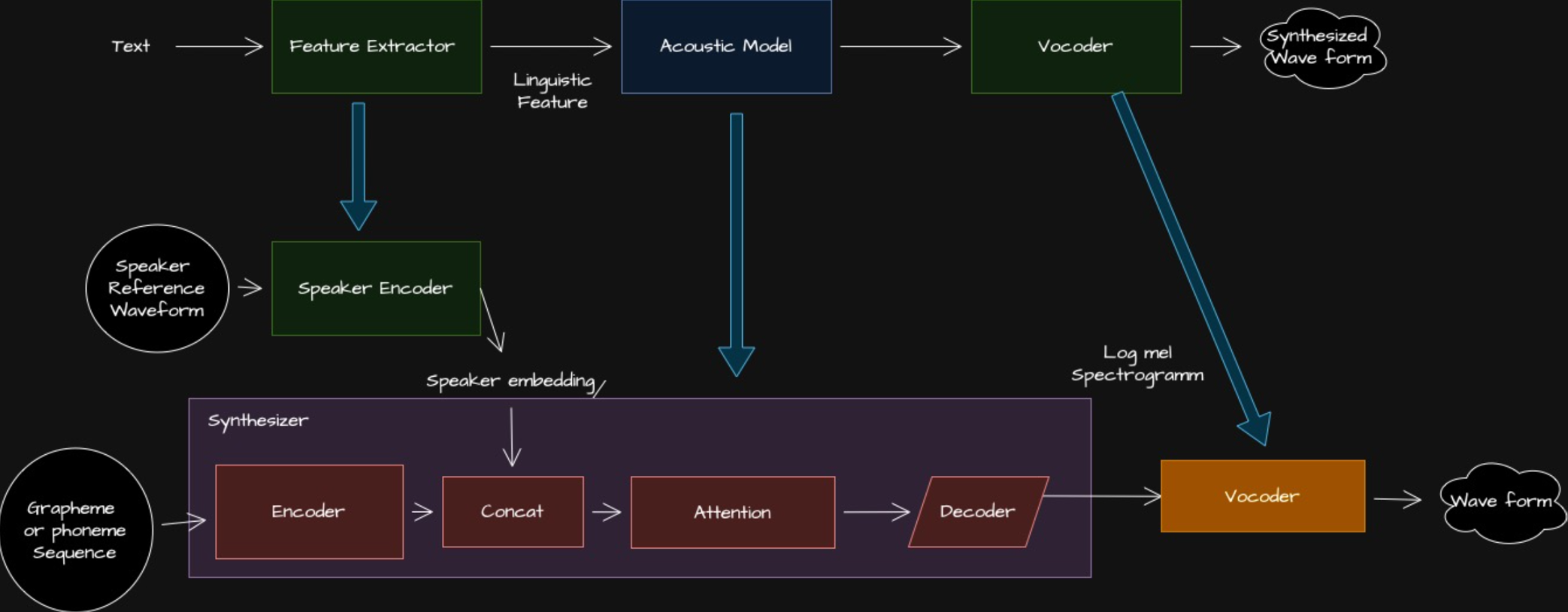
RTVC 的核心在于它的三阶段架构:
- Speaker Encoder(说话人编码器)
- 使用 GE2E 损失函数,从参考音频中提取出一个固定维度的语音嵌入(voice embedding),捕捉说话人的独特音色特征。
- Speech Synthesizer(语音合成器)
- 基于 Tacotron 架构,输入语音嵌入和目标文本后,输出对应的梅尔频谱图(mel spectrogram)。
- Vocoder(声码器)
- 利用 WaveRNN 模型,将梅尔频谱图转换为最终的音频波形,实现逼真的语音合成。
这三部分分工明确,又相互协作,使得整个流程既高效又灵活。更重要的是,RTVC 对硬件要求不高,普通的 GPU 即可运行,甚至 CPU 也能勉强应对。
核心功能亮点
| 功能 | 描述 |
|---|---|
| 🌟 快速克隆 | 仅需 5 秒语音即可生成模型 |
| 🚀 实时性 | 支持即时语音合成,延迟极低 |
| 📦 开源友好 | 提供完整的代码库和预训练模型 |
| 🧠 多语言支持 | 可扩展至多种语言的语音合成 |
使用场景:从游戏到诈骗检测
RTVC 的应用非常广泛,以下是一些典型的使用场景:
1. 游戏与影视制作
想象一下,在开发一款角色扮演游戏时,你可以用 RTVC 快速为每个角色定制独特的语音风格。只需提供一小段语音,AI 就能为你生成整套对话内容。
2. 虚拟助理与客服
RTVC 可以帮助构建个性化的虚拟助手。比如,你希望你的智能音箱用朋友的声音回答问题,现在可以轻松实现。
3. 教育与培训
教师可以用自己的声音创建教学音频材料,或者让学生练习发音,提升学习效率。
4. 语音伪造检测
虽然 RTVC 是语音克隆工具,但它也被用于测试语音伪造检测系统的性能。因为其生成的语音质量较高,能够模拟真实人类语音,因此被多个学术团队用作测试基准。
快速体验指南:X 分钟快速搭建语音克隆系统
对于刚接触 RTVC 的开发者来说,最关心的问题莫过于:“怎么开始?”其实,只要按照步骤操作,即使是新手也可以很快上手。
1. 安装依赖
首先确保你已经安装了 Python(建议 3.7 版本)。接着安装 PyTorch 和 ffmpeg。PyTorch 的安装可以通过官网选择适合你系统的版本和 CUDA 支持。
pip install torch torchvision torchaudio
2. 下载预训练模型
RTVC 提供了自动下载预训练模型的功能,无需手动操作。但如果网络不稳定,可以手动下载并放置到指定目录。
3. 运行示例
在完成上述步骤后,可以尝试运行官方提供的 demo 工具:
python demo_cli.py
这条命令会启动一个简单的命令行界面,让你快速体验语音克隆的效果。
4. 图形化界面(推荐)
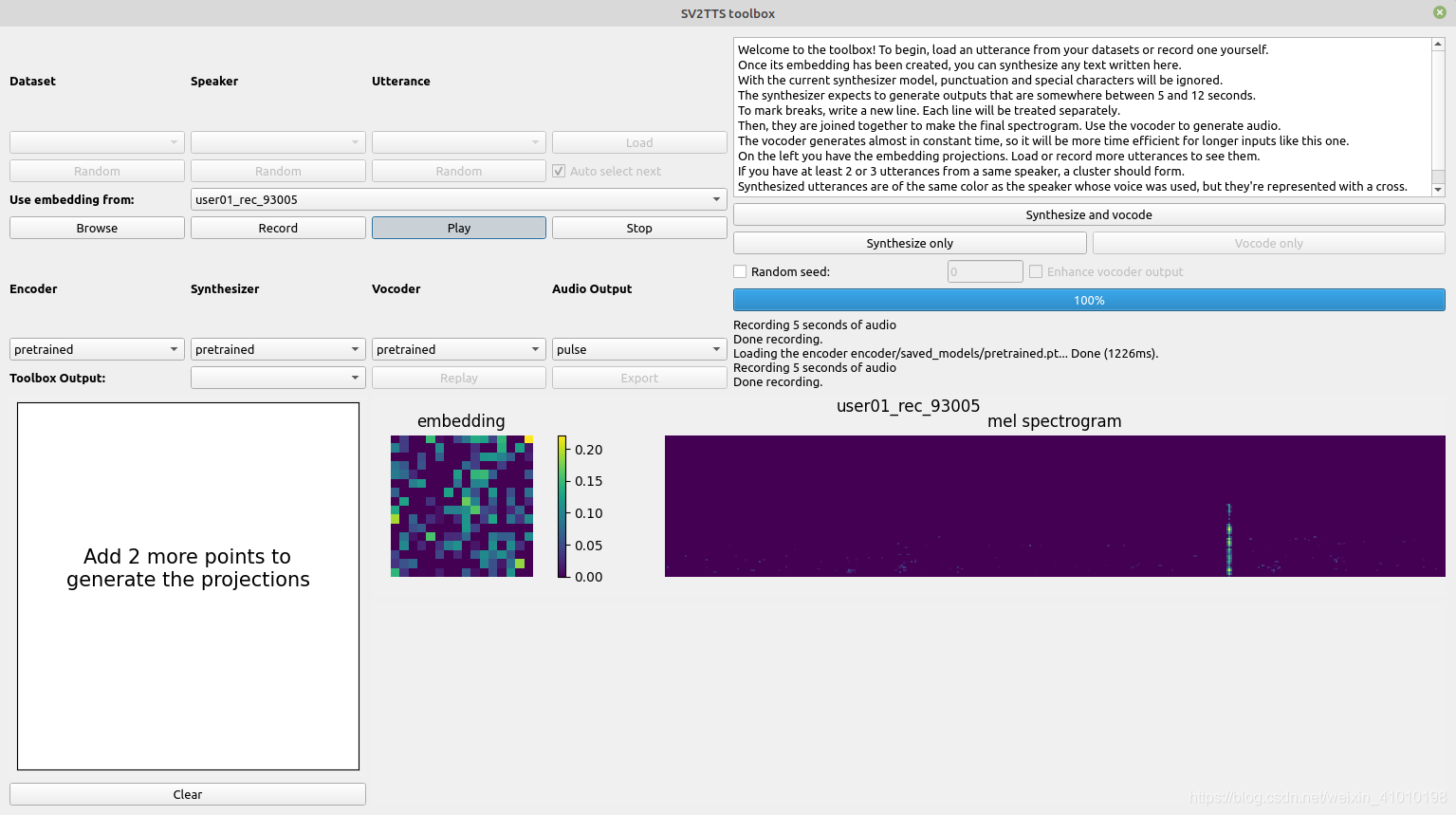
如果你喜欢图形化操作,可以运行 demo_toolbox.py 启动一个交互式 UI。它可以展示语音嵌入、生成的频谱图,并允许你直接播放生成的语音。
python demo_toolbox.py
5. 自定义语音
如果你想用自己的语音进行克隆,只需要准备一段清晰的音频文件(如 wav 或 mp3),然后按照文档提示上传即可。项目还提供了录音工具,方便你直接录制语音样本。
技术细节:为什么它能做到如此之快?
RTVC 的成功离不开其背后的技术选型和优化策略。我们来简单聊聊它的核心技术。
1. 模型架构选择
RTVC 使用了 SV2TTS 框架,这是一种专注于从语音验证任务迁移至多说话人语音合成的结构。这种设计使得模型可以快速适应新语音样本,而不必重新训练整个系统。
2. 语音编码器(GE2E)
GE2E 是一种通用端到端损失函数,专门用于说话人验证。它可以在少量语音数据下准确地提取语音特征,这是 RTVC 实现“5秒克隆”的关键。
3. WaveRNN 与 Tacotron
WaveRNN 是一个高效的声码器,负责将频谱图还原成音频波形。Tacotron 则是语音合成的核心,它可以根据文本生成语音的频谱表示。两者配合,实现了高质量的语音合成。
4. 性能优化
RTVC 在模型压缩和推理加速方面做了大量工作。例如,它通过剪枝和量化技术,降低了模型的计算复杂度,从而提升了运行效率。这也是为什么它能在普通硬件上实现实时语音合成的原因之一。
延伸阅读:探索更多可能性
如果你对 AI 语音合成感兴趣,不妨亲自试一试 RTVC。也许你会发现,AI 不再是遥不可及的概念,而是触手可及的工具。未来,语音克隆或许将成为我们日常生活的一部分,就像今天的手机语音助手一样,融入我们的世界。
以下是一些值得进一步了解的资源:
- 如果你想了解更多关于语音克隆技术的发展,推荐阅读 CoquiTTS —— 一个更新、更全面的语音合成框架。
- 如果你对深度伪造技术感兴趣,可以看看 MetaVoice-1B —— Facebook 推出的高质量语音生成模型。
- 如果你担心语音克隆的滥用问题,不妨了解一下 Deepfake Detection Challenge (DFDC) —— 一个致力于提升深度伪造检测能力的竞赛项目。
结语:AI 让每个人都能拥有“声音”
语音克隆不再是实验室里的黑科技,而是走进了我们的日常。通过 RTVC,我们可以看到 AI 技术的飞速发展,也感受到它带来的无限可能。
如果你正在寻找一个有趣又实用的开源项目,RTVC 绝对值得一试。它不仅能帮你解决语音相关的难题,还能激发你对 AI 的兴趣和创造力。
欢迎留言分享你的体验,或者谈谈你对语音克隆的看法。我们一起探讨 AI 的边界在哪里,又该如何更好地利用它!
关注 GitHubShare(githubshare.com),发现更多精彩内容!
感谢大家的支持!你们的支持是我继续更新的动力❤️
热门推荐










相关文章
关于
